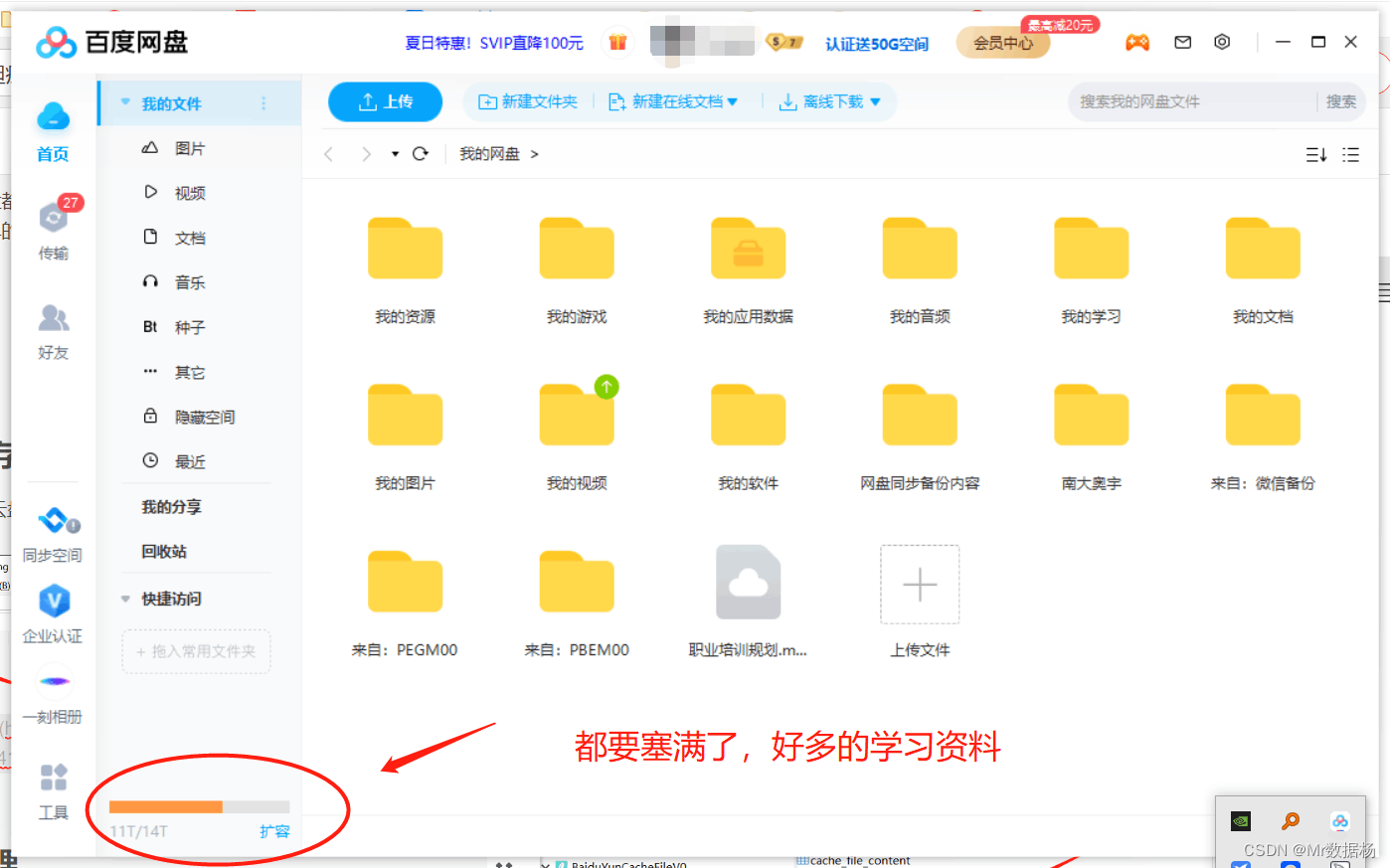
有莫得头疼过百度云盘齐要地满了,但是又莫得器用能剔除多半重迭无须的文献?这里教你一个简便的治安九儿 巨乳,通过整理目次的神情来责罚咱们云盘中无须的文献吧。
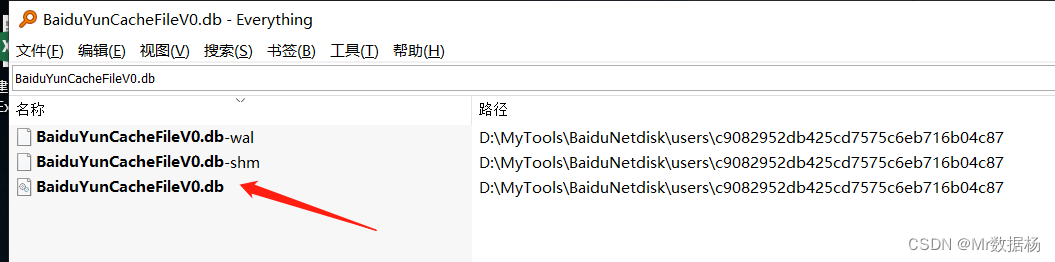
使用 Everything 找到云盘缓存 db 文献,复制到剧本的目次下。
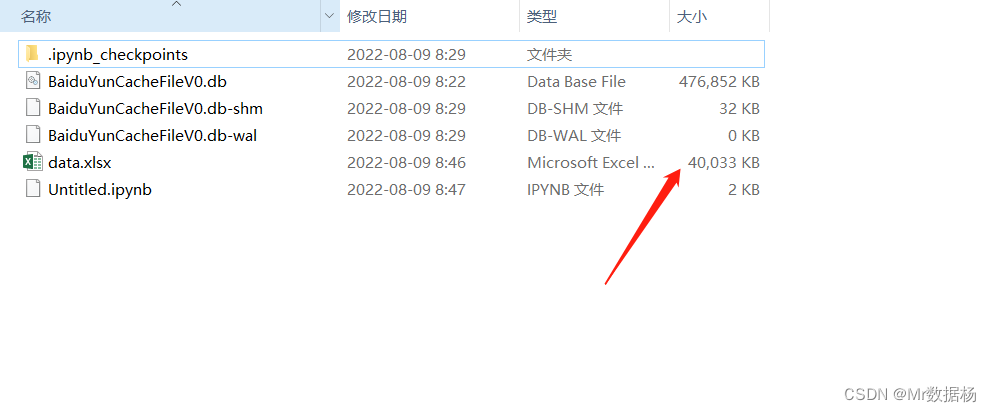
咱们发现这个是一个 sqlite3 的文献,用 Navicat 翻开先望望。

咱们统共云盘的文献以及对应的旅途保存在 cache_file 中,成功导出可能会有些问题,是以咱们用 pandas 来责罚数据就不错了。

我的云盘导出来了 40MB 的目次数据,看着齐头疼。
把云盘的目次数据导出到 excel,后去该奈何责罚就奈何责罚吧。代码荒谬少,如若可爱用 python 责罚就用 pandas 责罚,如若嗅觉有贫苦成功在 excel 中责罚就不错了。

这个由于百度云盘莫得对应的API接口不错使用爬虫的神情进行网页的操作对重迭数据进行删除,但是容易误操作,是以也曾手动把要责罚的数据整理出来然后进行操作把。
通过文献称号判断重迭,有了成果后续我方责罚就好了。
到此这篇对于Python终了一键整理百度云盘中重迭无须文献的著述就先容到这了九儿 巨乳,更多磋磨Python整理重迭文献实质请搜索剧本之家往常的著述或持续浏览底下的磋磨著述但愿民众以后多多复旧剧本之家!
您可能感兴味的著述: python终了自动整理文献 Python终了批量自动整理文献 Python剧本终了一键自动整理办公文献 Python终了计帐重迭文献功能的示例代码 Python自动化办公之计帐重迭文献详解 诈欺Python删除电脑中重迭文献的治安